Open Science and
Workshop
Quirin Würschinger
LMU Munich
October 19, 2023
> whoami
Quirin Würschingerq.wuerschinger@lmu.de
Current work
research
lexical innovation on the web and in social networks
variation and change in language use and social polarization in social networks
using Large Language Models (LLMs) like ChatGPT for research in linguistics and social science.
teaching : corpus linguistics and research methodology
Promoting Open Science in (computational) linguistics at LMU
teaching and applying reproducible corpuslinguistic methods
creating and sharing corpora among researchers and students
Open Open Science workshopFocus on …
ask questions
discuss
apply and practice
collaborate
Time table
intro
09:00
Open Science principles
10:30
~
version control
10:50
project structure
12:00
~
code
13:15
data and methods
14:40
~
publishing
15:00
authoring
15:25
recap, open issues, feedback
16:00
16:30
Addressing different backgrounds and goals
Backgrounds and interests
CAIS: Forschung zu Digitalisierung und Digitale Gesellschaft
research fiels
education and pedagogy
political science
sociology
communications studies
…
data and methods
qualitative interviews
text analysis
quantitative surveys
experimental designs
social media studies
…
Survey: main interests
reproducible workflows
managing files and folders
programming with Python and R
plain text authoring
data and methods
text analysis
social media analysis
questionnaires
publishing
sharing data and code
authoring papers
Who are you?
Please briefly introduce yourself …
name
place and position
your research interest in about 3 sentences for someone outside your field
What is Open Science?
Why should we do Open Science?
source
dataset/sample size
effect sizes
selection/number of relationships
flexibility in design
financial interests
hype around topic/field
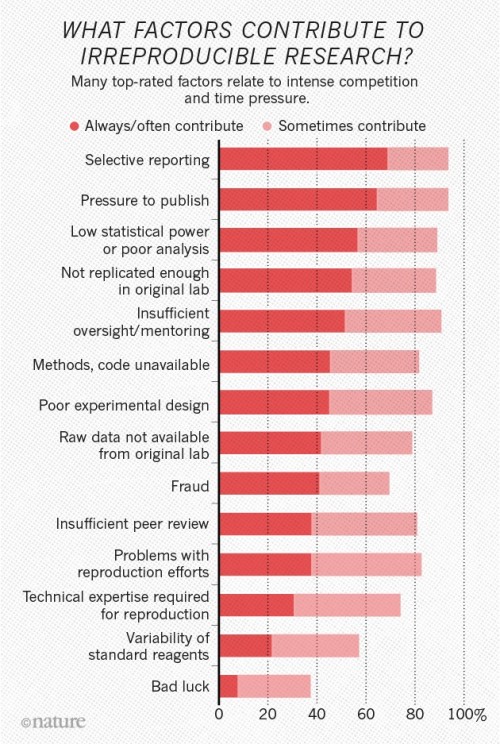
What are the reasons why science can go wrong?
Roles in Open Science
Funders
make open science part of the selection process, and conditions for grantees conducting research.
Publishers
make open science part of the review process, and conditions for articles published in their journals.
Institutions
make open science part of academic training, and part of the selection process for research positions and evaluation for advancement and promotion.
Societies
make open science part of their awards, events, and scholarly norms.
Researchers
enact open science in their work and advocate for broader adoption in their communities.
(Center for Open Science )
Who profits from Open Science?
source
What is Open Science to you?
What do you find interesting, important, or attractive about Open Science?
https://tinyurl.com/opnsci
Learning outcomes
::: {.content-visible when-format=“revealjs”} # Implementing an open and reproducible workflow
version control
project structure
code
data and methods
authoring
publishing
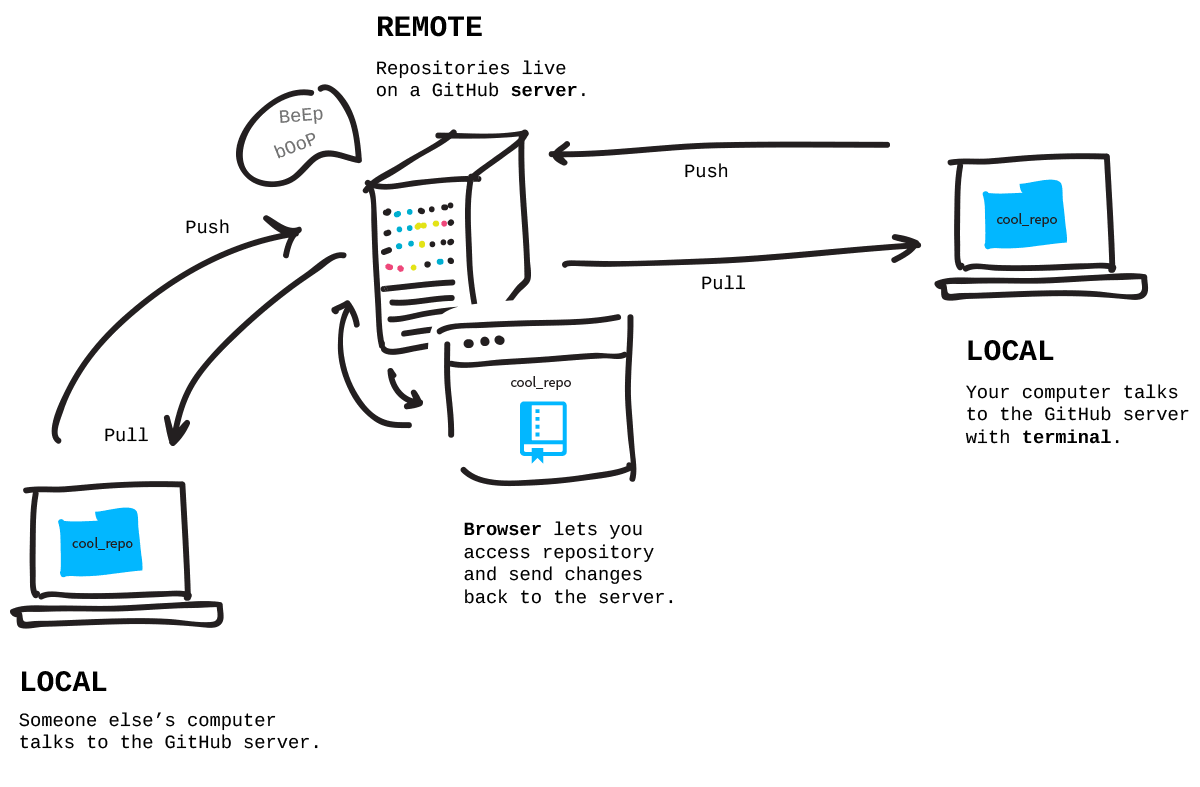
Version control
git and GitHub/GitLab
git
software on your machine
git add src/tests.pygit commit -m 'add tests' git push
GitHub and GitLab
services on a remote server
How to set up a GitHub repository
set up git
Installing git: see tutorial
Using git:
from the command line
using a standalone GUI1 tool; e.g.:
from within your editor/IDE2 ; e.g.:
set up GitHub
tutorial
setting up git user information (name, passwort)
setting up GitHub authentication
setting and storing authentication (‘token’)
create a repository on GitHub
(create GitHub account)
click on New (https://github.com/new )
specify repo name 1
specify description
specify visibility: private or public
select Add a README file
specify licence 2
clone repositoriesgo to the folder where you want your project to live
git clone https://github.com/wuqui/opensciws.git
adding, commiting, and pushing changes(source)
git add src/tests.pygit commit -m 'add tests' git push
Let’s not pretend we’re all geniuses …
File names
File names should be:
machine-readable
human-readable
consistent
avoid non-ASCII characters (e.g. umlauts like ü, ä)
optional: play well with default ordering (e.g. include timestamps)
File structure
.
├── analysis <- all things data analysis
│ └── src <- functions and other source files
├── comm
│ ├── internal-comm <- internal communication such as meeting notes
│ └── journal-comm <- communication with the journal, e.g. peer review
├── data
│ ├── data_clean <- clean version of the data
│ └── data_raw <- raw data (don't touch)
├── dissemination
│ ├── manuscripts
│ ├── posters
│ └── presentations
├── documentation <- documentation, e.g. data management plan
└── misc <- miscellaneous files that don't fit elsewhere
General principle
keep the ‘inputs’ of your project/code (e.g. data) separate from its outputs (e.g. plots).
Practice: project management
You have until 11:50 h to work on either …
developing a project structure for your needs from scratch
refactoring/cleaning an existing project1
Optionally: set up version control via git/GitHub for this project.
Reproducibility (crisis)
source
Reproducibility et al.
Testing code
Why we should test code
source
not all our projects have that high stakes
Professional testing
source
Types of tests
Testing frameworks
Python: pytest
R: testthat
Analogy
during the process of manufacturing a ballpoint pen, the cap, the body, the tail, the ink cartridge and the ballpoint are produced separately and unit tested separately.
When two or more units are ready, they are assembled and integration testing is performed, for example a test to check the cap fits on the body.
When the complete pen is integrated, system testing is performed to check it can be used to write like any pen should.
Acceptance testing could be a check to ensure the pen is the colour the customer ordered.
source
Testing example
using pytest for Python
Documenting code
Literate programming
’Literate programming is a methodology that combines a programming language with a documentation language ,
thereby making programs more robust , more portable , more easily maintained ,
and arguably more fun to write than programs that are written only in a high-level language.
The main idea is to treat a program as a piece of literature, addressed to human beings rather than to a computer.
The program is also viewed as a hypertext document , rather like the World Wide Web. (Indeed, I used the word WEB for this purpose long before CERN grabbed it!)’
Donald Knuth
Notebooks
who uses notebooks?
which ones?
good for novices & experts
Example using nbdev for Python
Literate testing with nbdev
Additional benefits of nbdev
simple, integrated testing
continuous integration dependency management
publishing code for PyPI and conda
publishing documentation via Quarto
good for novices & experts
covers about 80% of programming setup for free
more about Quarto later
R: Quarto and RMarkdown
Diversity in data and methods
CAIS: Forschung zu Digitalisierung und Digitale Gesellschaft
research fiels
education and pedagogy
political science
sociology
communications studies
…
data and methods
qualitative interviews
text analysis
quantitative surveys
experimental designs
social media studies
…
Reasons to share your data
To allow the possibility to fully reproduce a scientific study.
To prevent duplicate efforts and speed up scientific progress . Large amounts of research funds and careers of researchers can be wasted by only sharing a small part of research in the form of publications.
To facilitate collaboration and increase the impact and quality of scientific research.
To make results of research openly available as a public good , since research is often publicly funded.
How to share your data
Turing Way tutorial
Step 1: Select what data you want to share; eg.:
ethical concerns
commercial concerns
Step 2: Choose a data repository or other sharing platform
Step 3: Choose a licence and link to your paper and code; e.g.:
Step 4: Upload your data and documentation
good file organisation
appropriate file formats (e.g. csv > xlsx)
Excel issues
formatting
thousands separators: , vs .
date conversion
formulas
Sharing social media data
source
Obstacles to data-sharing
Reason 1: Preparing data for sharing is resource-intensive
Reason 2: Not enough credit for data sharing
Reason 3: Lack of confidence and knowledge
Reason 4: Data protection laws
Reason 5: Platform terms of service
Reason 6: Copyright
Reason 7: Informed consent
Reason 8: Ethical challenges
Reason 9: Lack of common standards
source
additional reason: sharing not considered (necessary)
ethical and privacy : paper on incest on Twitter
The case of Twitter
stage 1: access costly & legal grey area for scraping
stage 2: Research API 🎉
stage 3: Elon Musik → X → …
Routes to open access publishing
source
Preregistration
What is preregistration?
When you preregister your research, you’re simply specifying your research plan in advance of your study and submitting it to a registry.
Preregistration separates hypothesis-generating (exploratory) from hypothesis-testing (confirmatory) research.
Both are important.
But the same data cannot be used to generate and test a hypothesis, which can happen unintentionally and reduce the credibility of your results.
Addressing this problem through planning improves the quality and transparency of your research.
This helps you clearly report your study and helps others who may wish to build on it.
Open Science Center tutorial
The preregistration process
source
Avoiding pitfalls through preregistration
source
HARKing : hypothesizing after results are known
Outlets
ArXiV
preprints
Zenodo
all kinds including data, code, preprints, etc.
GitHub and GitLab
code, software
Open Science Framework
all kinds including data, code, preprints, preregistration, etc.
Software Heritage
archival of code (long-term)
Papers with Code
code and data for and with papers, mostly Machine Learning
…
Benefits of Markdown
Markdown provides semantic meaning for content in a relatively simple way
You can write rich formatted content extremely quickly (compared to writing directly in HTML tags)
You can read Markdown easily in plain text before rendered by HTML
It doesn’t interrupt your workflow with the need to click buttons
It’s platform-agnostic so your content is not tied to the format of your editor
Multi-purpose publishing
Code
Python
R
Articles
Presentations
Websites
Personal websites and blogs
Authoring a Quarto document
You have until 16:00 h to,
based on Quarto’s excellent getting started guide ,
install Quarto
make an example text document using Quarto Markdown syntax (optional: clone my demo repo )
render the document to multiple output formats (pdf, html, docx, etc.)
further steps
publishing your document(s) as a website on GitHub pages (see tutorial )
refactoring existing document (e.g. paper, website) to Quarto Markdown
Recap, open issues, feedback
version control
project structure
code
data and methods
authoring
publishing

















































{kind=link}
{kind=link}
{kind=link}
{kind=link}















