Course Wrap-up & Synthesis
Seminar ‘Corpus Linguistics’
July 24, 2025
Sessions 01-06: Foundations & Core Methods
Building the foundation
- Organisation & introduction to corpus linguistics
- Sketch Engine skills (concordancing, frequency)
- Lexical innovation & diffusion patterns
- Morphology & word-formation processes
- Meaning analysis, collocations, word sketches (clipping study, Hilpert, Correia Saavedra, and Rains (2023))
- Creating corpora (principles & practice)
→ Core skills acquired: corpus search, frequency analysis, morphological investigation, corpus design
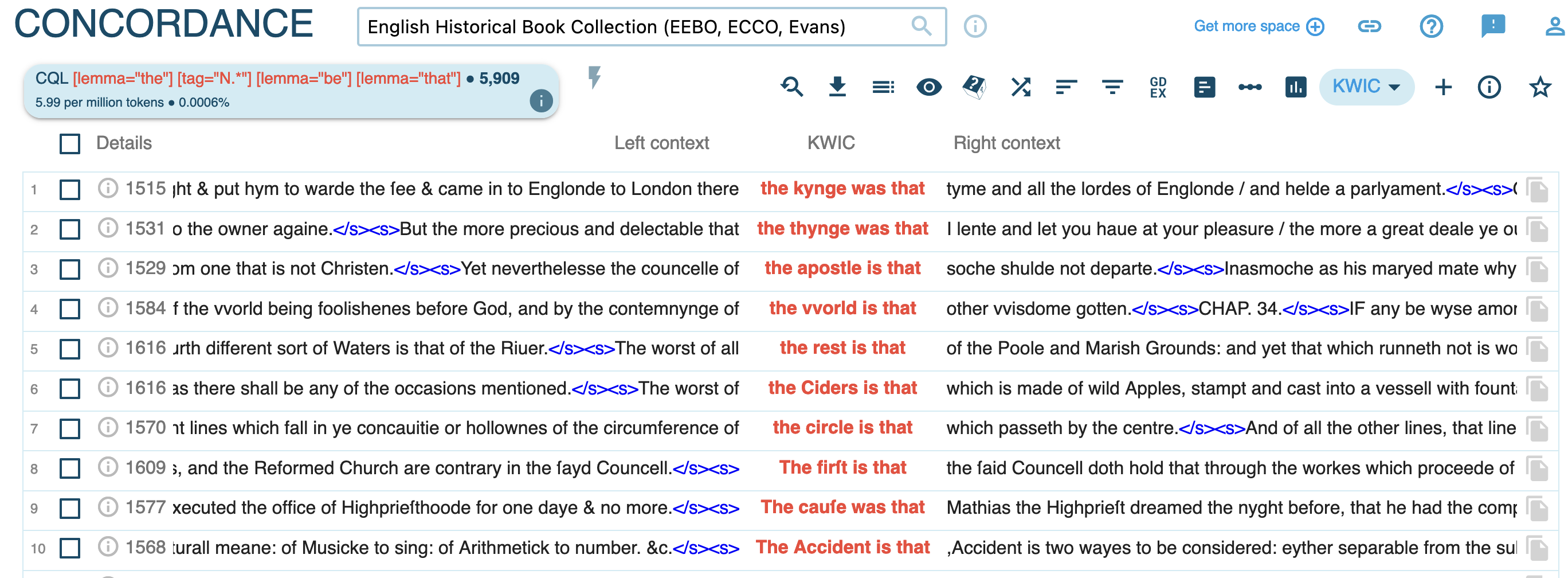
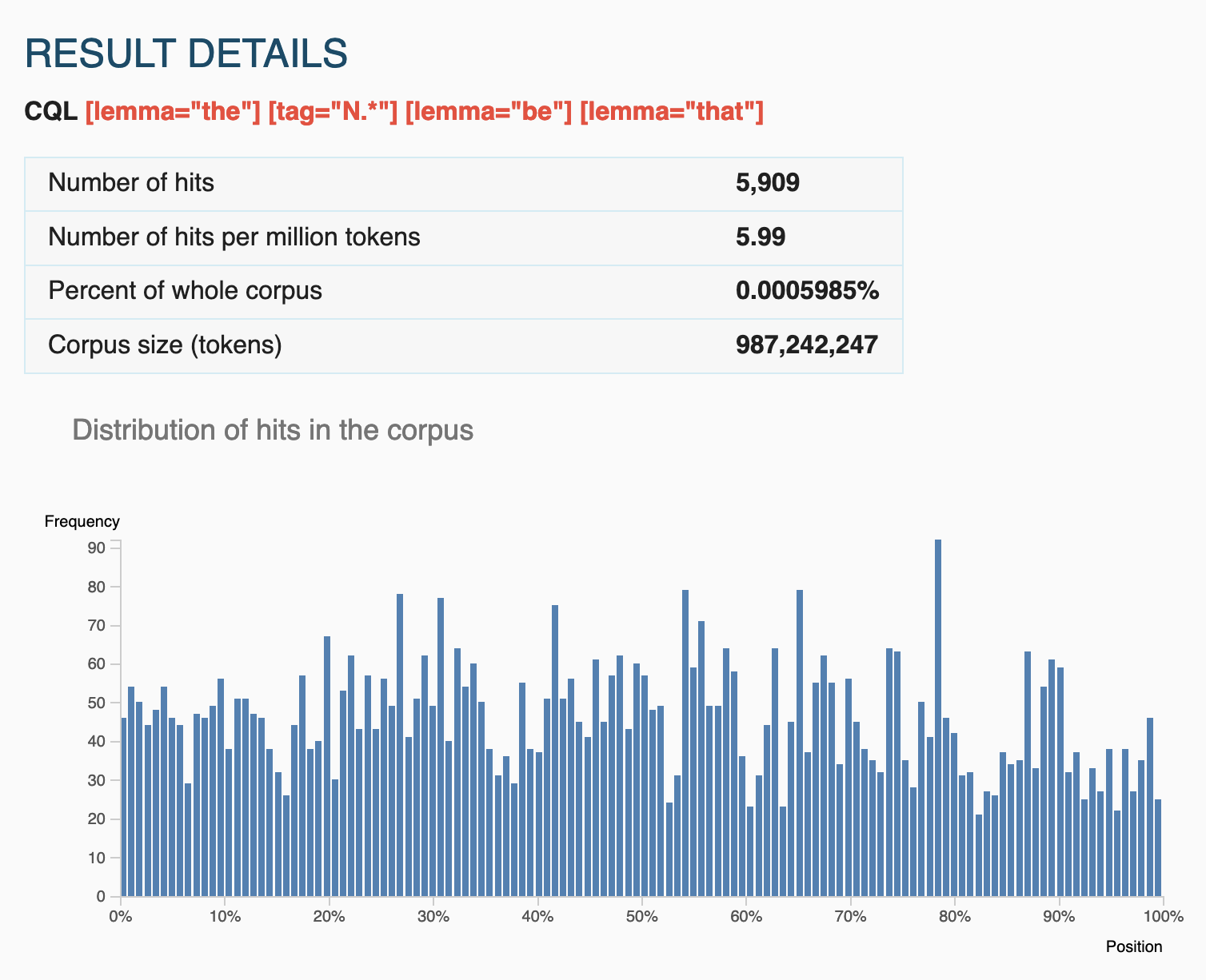
Sessions 07-10: Advanced Applications
From methods to research
- Syntax analysis (constructions, CQL, entrenchment research)
- Research project planning & term paper methodology
- Linguistic variation (tag questions, social factors)
- Language change (modal verbs, diachronic analysis)
→ Research skills developed: syntactic investigation, sociolinguistic analysis, historical corpus research, project design


Language Change: Modal Verbs Over Time
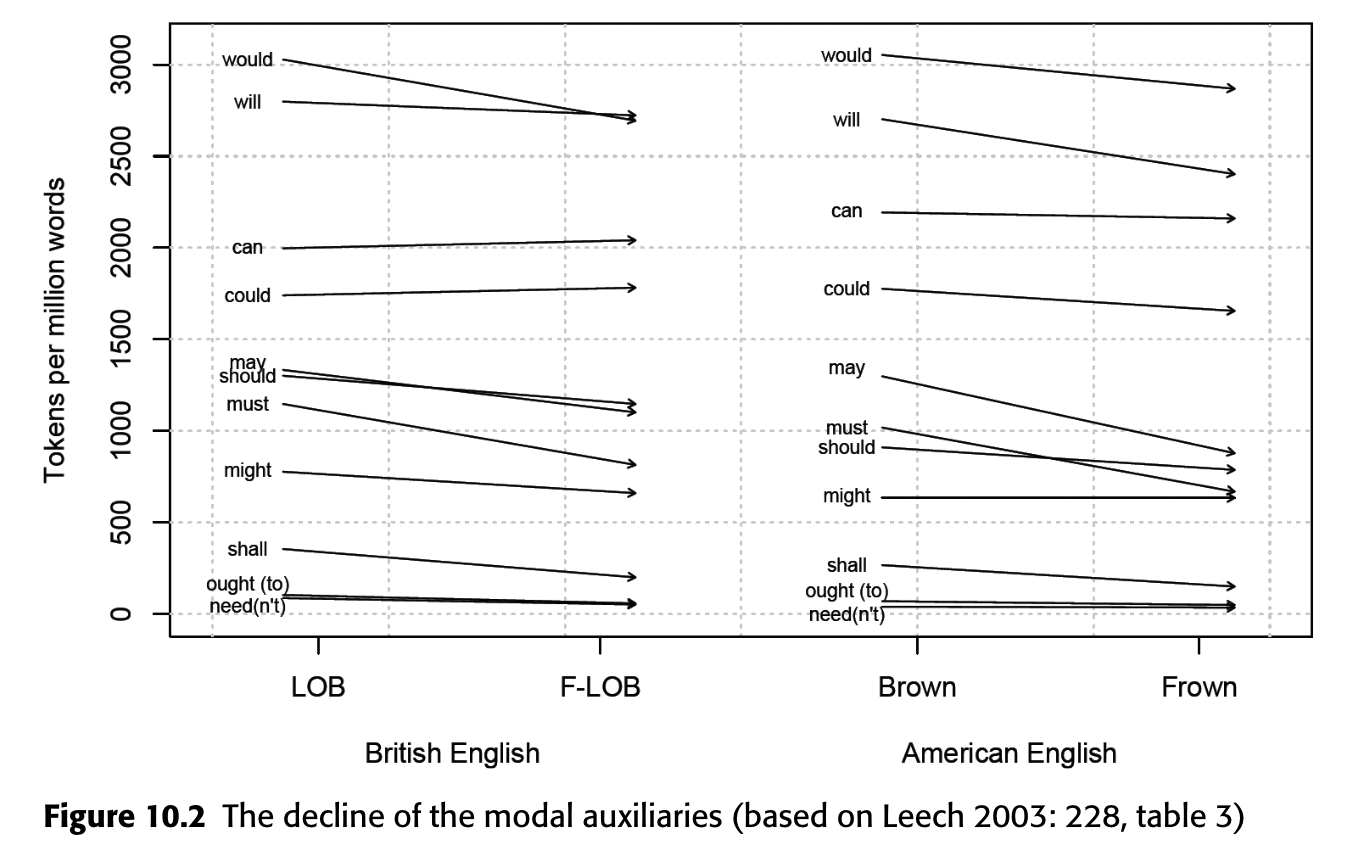
Modal verb frequency changes over time
Session 10: tracking systematic language change patterns
Language Levels & Phenomena
Corpus methods across linguistic levels
| Level | Phenomena | Methods | Focus |
|---|---|---|---|
| Lexis | Innovation, diffusion | Frequency tracking, diachronic analysis | Patterns of lexical change |
| Morphology | Word-formation, clipping | Collocational analysis, meaning comparison | Form-meaning relationships |
| Syntax | Constructions, CQL patterns | Frequency analysis, entrenchment measures | Usage-based grammar |
| Sociolinguistics | Variation, change | Social factor analysis, diachronic comparison | Language and society |
→ Corpus linguistics = versatile methodology across all language levels
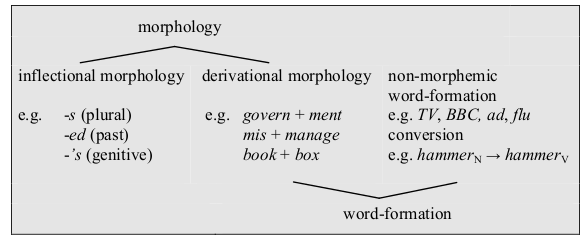
Theoretical framework from Session 04
Methodological Skills
Your corpus linguistics toolkit
Search & Analysis:
- Sketch Engine: concordancing, frequency lists, word sketches
- CQL (Corpus Query Language): advanced pattern searches
- Collocational analysis: meaning through co-occurrence
- Diachronic comparison: tracking change over time
Research Design:
- Corpus selection: appropriate data for research questions
- Hypothesis formation: testable predictions about language use
- Critical evaluation: corpus limitations and biases

Advanced search capabilities
Corpus Resources & Data Access

English corpora overview
Sessions 06 & 10: from corpus principles to historical English corpora